
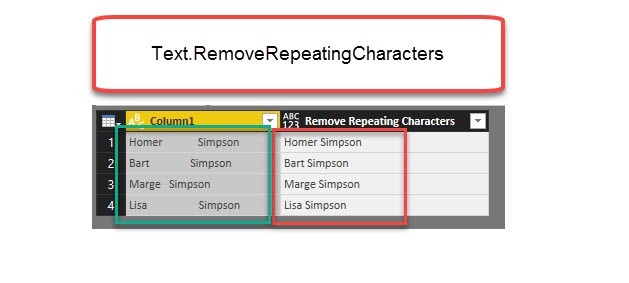
Repeating spaces often cause problems when cleaning up your data. My new function “Text.RemoveRepeatingCharacters” can come to the rescue here.
Imagine you have a table like this:

Challenge
To further work with this data, it would often be best if there was just one space between the words and not many.

The following function will do this for you:
Function Text.RemoveRepeatingCharacters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| let func = | |
| (String as text, optional Delimiter as text) as text => | |
| let | |
| delimiter = if Delimiter = null then " " else Delimiter, | |
| TextToList = List.Buffer(Text.Split(String, delimiter)), | |
| FilterList = List.Select(TextToList, each _ <> ""), | |
| Result = Text.Combine(FilterList, delimiter) | |
| in | |
| Result | |
| , documentation = [ | |
| Documentation.Name = " Text.RemoveRepeatingCharacters | |
| ", Documentation.Description = " Removes repeating characters of the delimiter from a <code>String</code> | |
| " , Documentation.LongDescription = " Removes repeating characters of the delimiter from a <code>String</code>. <code>Delimiter</code> is by default set to space/blank. | |
| ", Documentation.Category = " Text | |
| ", Documentation.Source = " http://wp.me/p6lgsG-M9 . | |
| ", Documentation.Author = " Imke Feldmann: www.TheBIccountant.com . | |
| ", Documentation.Examples = {[Description = " Removes repeating characters of the delimiter from a string: https://wp.me/p6lgsG-M9 . | |
| " , Code = " RemoveRepeatingCharacters(""Imke Feldmann"") | |
| ", Result = " ""Imke Feldmann"" | |
| "]}] | |
| in | |
| Value.ReplaceType(func, Value.ReplaceMetadata(Value.Type(func), documentation)) |
How to use
It takes 2 arguments: The Text/String and the Delimiter. The delimiter is an optional argument and by default set to space ” “. So you can leave it blank if that’s fine for you or enter a different value (like “,” for a comma) if needed.
How it works
It splits the text up into a list using the delimiter from the 2nd parameter (4: TextToList). Where one delimiter directly follows another, the element in the list will be empty. The next step (5: FilterList) then filters the list and removes these empty fields. In the last step (6: Result) the remaining (non-empty) fields will be reassembled, using the delimiter again. That way, just one delimiter will be left.
Edit 28-Jan-2018: While searching the web to see if one of my next blogpost-topics have already been published somewhere else already, I came across Ivan Bond’s blogpost who used this same technique over 2 years ago here: https://bondarenkoivan.wordpress.com/2015/10/11/transform-table-column-using-own-function-in-power-query/ . It’s a very good read and you will also learn how to use a function like this to transform an existing column instead of adding a new one to perform the operation like in my example above, so don’t miss it.
Edit: If you are wondering why I didn’t use a recursive approach via List.Accumulate or List.Generate for it, check out Rick de Groots article where he does a performance comparison of this approach against them:
Removing Excess Spaces Between Words in Power Query (gorilla.bi)
This is by far the fastest approach 🙂
Enjoy & stay queryious 🙂
Great, thank you very much
Pingback: Removing Repeating Characters In Power Query – Curated SQL
Imke, that is a very elegant solution!
Thank you Chris 🙂
Pingback: Power Query and a new Power BI Desktop update | Guy in a Cube
Imke – rather than create a custom function — my approach has been to nest the three functions into a single line of code ie: Text.Combine ( List.Select( Text.Split (….. ) ) ) — enabling the query to execute seamless – absent the invocation requirement associated with a custom function.
Thanks – Drewbbc.
Hi Drew, I wasn’t a fan of custom functions for quite a while as well.
But with the prospect of soon being able to store them in libraries that make them available just like native functions, I turn everything into a custom function meanwhile 🙂
Imke,
A nice post. It got me thinking of how to do the opposite or something like that. I want to look for a character string that is in the following format: 99-99-999-99×9 where 9 is a numeric value and x is a character value. Much like a sin or postal code.
Do you have any insight on how to do that?
thx,
wes
Thank you.
Not sure if I understood your request correctly, but please check this query:
letString = "99-99-999-99x9",
Test = "asldf asldkfj 12-34-567-89a0 asfdkjö sfadjk",
fnProfile = (String) => {Text.PositionOfAny(String, {"0".."9"}, Occurrence.All), Text.PositionOfAny(String, {"A".."z"}, Occurrence.All), Text.PositionOfAny(String, {"-"}, Occurrence.All)},
StringProfile = fnProfile(String),
Custom1 = Text.Split(Test, " "),
Custom2 = List.Select(Custom1, each fnProfile(_)=StringProfile)
in
Custom2
I think so.
I will try it in Power BI on the weekend. I plan to use it to a column like this one:
Title
name change for01-07-009-06W2
12-04-010-28W1 and 12-05-010-28W1 overlapping when they should not be
change surface hole location for well 16-23-002-01W2
Very useful function. You could make the delimiter optional and use a space as default.
Thank you very much Franz,
that’s an excellent idea!
Updated already 🙂
/Imke
And just to avoid errors when the input is null you could make the first argument nullable text and check for nulls to avoid Text.Combine from speading errors. The version I use is:
( String as nullable text, optional TrimChar as nullable text ) as nullable text =>
let
trimChar = if TrimChar is null then ” ” else TrimChar as text,
Split = Text.Split( String, trimChar ) as list,
Remove = List.RemoveItems( Split, { “” } ) as list,
Combine = Text.Combine( Remove, trimChar ) as nullable text,
Result = if String null then Combine else null as nullable text
in
Result
Thanks for all the nice articles.
Cool – thanks a lot!
It appears that if the input string contains multiples of the delimiter to remove at the end of the string, this removes ALL of those occurrences from the end of the input string and not leaving just the one occurrence as expected. Is anyone else seeing this behavior? Try this as String –> “Johnny Be Good???” and a “?” as the Delimiter. Version 1908 Build 11929.20708
Hi PT,
This is a bug. Fixed it.
Thanks for the heads up.
/Imke