
If you’ve been following my blog for a while, you might have noticed my interest in incremental load workarounds. It took some time before we saw the native functionality for it in Power BI and it was first released for premium workspaces only. Fortunately, we now have it for shared workspaces / pro licenses as well and it is a real live saver for scenarios where the refresh speed is an issue.
However, there is a second use case for incremental refresh scenarios that is not covered ideally with the current implementation. This is where the aim is to harvest and store data in Power BI that will become unavailable in their source in the future or one simply wants to create a track of changes in a data source. Chris Webb has beaten me to this article here and describes in great detail how that setup works. He also mentions that this is not a recommended setup, which I agree. Another disadvantage of that solution is that this harvested data is only available as a shared dataset instead of a “simple” table. This limits the use cases and might force you to set up these incremental refreshes in multiple datasets.
Dataflows to the rescue
Recently I discovered a nice alternative that allows you to use Power Query for such a task. It stores the data in an entity of the Common Data Service (short: CDS). From there it can be queried by the Power Platform applications (unfortunately there is currently no connector for it in Power Query in Excel). Please note that this requires appropriate licensing.
Please also note, that currently not all Power Query features are available in Dataflows. Most notable limitations are missing connectors and custom functions not being available. But as Microsoft seems to aim for feature parity, this looks like a very promising path.
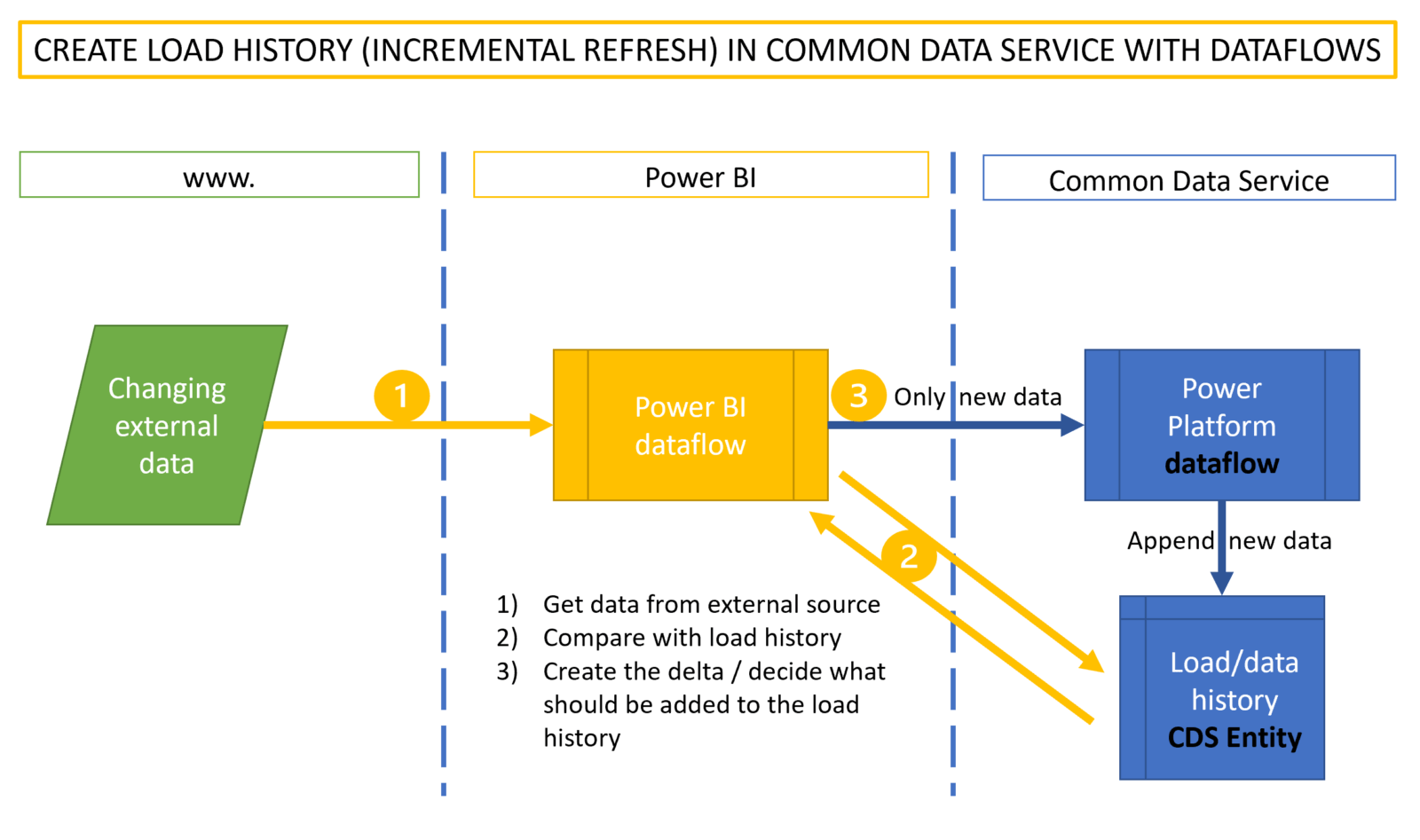
The technique uses a Power BI dataflow to regularly import the data from the source and (if necessary) compares it to the data already stored in the history table (sitting in CDS). It filters the new data that shall be added to the existing data. To transfer this data into the CDS, a Power Platform dataflow has to be used. Power BI dataflows currently cannot store data into CDS entities. So the Power Platform dataflow does nothing else than re-formatting and forwarding the content from the Power BI dataflow into the CDS entity. Reformatting is necessary due to the following limitations:
- Using data fields in Power BI dataflows will make that dataflow invisible from a Power Platform dataflow. So format your date fields as text and reformat them back to date in the Power Platform dataflow.
- Datetime fields will cause troubles when loading to the common data service entity. So either split them to a date and a time field or use them as a text field, if possible, instead.
Process overview

Overview of the incremental load scenario with Power Platform dataflows
Although I haven’t tested it, this should also be possible when your bring your own data lake storage.
Edit: As Maxim Zelensky has pointed out, reading all the data from the CDS entity to perform the comparison could slow the refresh process down considerably. It would be very cool, if one could use entity metadata to read/write the parameters needed for the delta load (like latest date for example). But for now, one would instead have to create a “Shadow entity” that stores just this data in a one row table that could be read much faster like so:

With “Shadow entity” containing metadata for delta load
Dataflow settings
I won’t go into the details on how to create dataflows here. Matthew Roche has you covered here , if they are new to you. Just want to point out some notable things:

Appending data to entities in the Common Data Service with dataflows
If you want to append new data to already existing data in the entities, you have to leave the “Delete rows that no longer exist in the query output” unchecked. Otherwise all your data will be deleted !!
To do this, you need to have a unique key in your table. But often this won’t be provided by your data source. Luckily there is an easy way to do this in the Power BI dataflow:
- Create a new column that contains “DateTime.LocalNow()” (this will return the current timestamp)
- Create an index column (this will create a unique number for each row in the refresh)
- Merge both new columns (this will create a value that will be unique in the history table)
Lastly, make sure to sync refresh time of both dataflows so that the Power BI dataflow refresh will be finished before the refresh of the Power Platform dataflow starts.
Enjoy and stay queryious 😉
If you need professional help to set this up in your environment, just send an inquiry to info@thebiccoutant.com.
Very exciting – the “Power Query Data Warehouse” I’ve been dreaming of for almost a decade is one step closer!
OT, but – I’ve only dabbled with CDS, but always been stumped by how to share results – it seems to only want to present new Entities to Power BI Authors using the same CDS log in?
Hi Mike,
I’m no expert on CDS either, but it works in my tenant just as any other cloud storage that can be accessed by other users with their organizational credentials/logins.
They must have access to the environment.
/Imke