
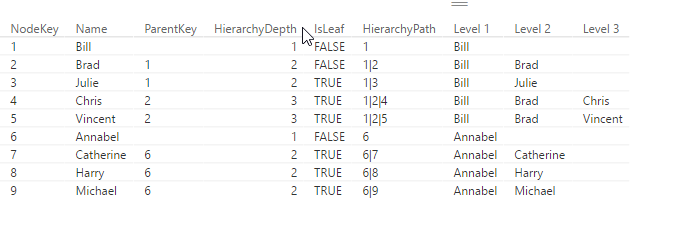
If you use DAX to flatten Parent-Child hierarchies you will end up with a table that has a static number of columns (like described here). If you need a dynamic solution instead, which creates just as many level-columns as there are needed for the current data, you can use DAX’s helper-tool Power Query (or Get Data in Excel) or the query-editor in PowerBI, which uses the language M.
Another advantage of this solution is that you can script the table creation in one step (only flaw: You still need to manually adjust your hierarchy though): But it saves time in creating the table, especially if you have many levels.
Update 2017-Dec-2: It also handles multiple parents now.
2 simple steps to flatten Parent-Child Hierarchies
- copy the following function,
- add a new step to your current table where you call this function, filling in the following parameters:
- table name (which is the name of the previous step in your M-query)
- name of the column with the child-key
- name of the column with the parent-key
- name of the column who’s values shall be shown in the levels (can also be child-key)

Call fnFlattenPCHierarchyFunction
Endless loops
If the relationships in your data are ambiguous, i.e. items stand in parent-child as well as child-parent-relationship to each other, and endless loop would occur. The newest version (V2 upwards) caters for this possibility and will generate a warning and return only the rows that are subject to the endless loop to examine.
And this is the code:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ///* | |
| let func = | |
| (ParChTable as table, | |
| ChildKey as text, | |
| ParentKey as text, | |
| LevelColumnName as text) => | |
| //*/ | |
| let | |
| /*/Debug Parameters | |
| ParChTable = SourceData_Loop, | |
| ChildKey = "NodeKey", | |
| ParentKey = "ParentKey", | |
| LevelColumnName = "Name", | |
| */ | |
| SelectRelevantColumns = Table.SelectColumns(ParChTable, {ChildKey, ParentKey, LevelColumnName}), | |
| #"Changed Type" = Table.TransformColumnTypes(SelectRelevantColumns ,{{ChildKey, type text}, {ParentKey, type text}}), | |
| ReplaceNulls = Table.ReplaceValue(#"Changed Type",null,"",Replacer.ReplaceValue,{ParentKey}), | |
| // CleanParChTable = Table.Distinct(ReplaceNulls , {ChildKey, ParentKey}), | |
| MissingParents = List.Buffer(List.Select(List.Difference(List.Distinct(Table.Column(ReplaceNulls , ParentKey)), List.Distinct(Table.Column(ReplaceNulls , ChildKey))), each _ <> "")), | |
| AddMissingParents = Table.Buffer(Table.Combine({ReplaceNulls , #table({ChildKey, LevelColumnName, ParentKey}, List.Transform(MissingParents, each {_, "Unknown TopLevel"& Text.From(List.PositionOf(MissingParents, _)), ""}))})), | |
| #"Merged Queries0" = Table.NestedJoin(AddMissingParents,{ChildKey},AddMissingParents,{ParentKey},"SelectRelevantColumns",JoinKind.LeftOuter), | |
| CheckIfIsLeaf = Table.AddColumn(#"Merged Queries0", "IsLeaf", each if Table.IsEmpty([SelectRelevantColumns]) then "yes" else "no"), | |
| #"Replaced Value1" = Table.ReplaceValue(CheckIfIsLeaf,null,"",Replacer.ReplaceValue,{ParentKey, LevelColumnName}), | |
| AddStartPath = Table.AddColumn(#"Replaced Value1", "Path", each Text.Trim(Record.Field(_, ChildKey)&"|"&Record.Field(_,ParentKey), "|")), | |
| #"Duplicated Column" = Table.DuplicateColumn(AddStartPath, LevelColumnName, "FirstName"), | |
| Feed = Table.DuplicateColumn(#"Duplicated Column", ParentKey, "FirstParentKey"), | |
| // Retrieve all parents per row | |
| fnAllParents = List.Generate(()=> | |
| [Result= Feed, Level=1, EndlessLoop = false, StopEndlessLoop = false], | |
| each Table.RowCount([Result]) > 0 and not [StopEndlessLoop], | |
| each [ Result= let | |
| #"Merged Queries" = Table.NestedJoin([Result],{ParentKey},AddMissingParents,{ChildKey},"Added Custom",JoinKind.Inner), | |
| #"Removed Columns1" = Table.RemoveColumns(#"Merged Queries",{ParentKey}), | |
| #"Expanded Added Custom" = Table.ExpandTableColumn(#"Removed Columns1", "Added Custom", {ParentKey, LevelColumnName}, {"ParentKey.1", "Name.1"}), | |
| #"Duplicated Column" = Table.DuplicateColumn(#"Expanded Added Custom", "ParentKey.1", ParentKey), | |
| #"Merged Columns" = Table.CombineColumns(#"Duplicated Column",{"Path", "ParentKey.1"},Combiner.CombineTextByDelimiter("|", QuoteStyle.None),"Path"), | |
| #"Merged Columns2" = Table.CombineColumns( #"Merged Columns" ,{LevelColumnName, "Name.1"},Combiner.CombineTextByDelimiter("|", QuoteStyle.None),LevelColumnName) | |
| in | |
| Table.Buffer(#"Merged Columns2"), | |
| Level = [Level]+1, | |
| EndlessLoop = List.Sort(List.Distinct(Table.Column(Result, ChildKey))) = List.Sort(List.Distinct(Table.Column([Result], ChildKey))), | |
| StopEndlessLoop = [EndlessLoop] | |
| ]), | |
| ConvertToTable = Table.FromList(fnAllParents, Splitter.SplitByNothing(), null, null, ExtraValues.Error), | |
| ExpandLevel = Table.ExpandRecordColumn(ConvertToTable, "Column1", {"Result", "Level", "EndlessLoop"}, {"Result", "Level", "EndlessLoop"}), | |
| ExpandLG = Table.ExpandTableColumn(ExpandLevel, "Result", {LevelColumnName, ParentKey, ChildKey, "Path", "FirstName", "FirstParentKey"}, {"Name", "ParentKey", "NodeKey", "Path", "FirstName", "FirstParentKey"}), | |
| FilterParents = Table.SelectRows(ExpandLG, each ([ParentKey] = null or [ParentKey] = "")), | |
| #"Removed Columns" = Table.RemoveColumns(FilterParents,{"ParentKey"}), | |
| #"Trimmed Text" = Table.TransformColumns(#"Removed Columns",{{"Path", each Text.Trim(_, "|")}}), | |
| ReverseOrderName = Table.TransformColumns(#"Trimmed Text",{{"Name", each Text.Combine(List.Reverse(Text.Split(_, "|")), "|")}}), | |
| ReverseOrderPath = Table.TransformColumns(ReverseOrderName,{{"Path", each Text.Combine(List.Reverse(Text.Split(_, "|")), "|")}}), | |
| #"Reordered Columns" = Table.ReorderColumns(ReverseOrderPath,{"NodeKey", "FirstParentKey", "Path", "FirstName", "Level", "Name"}), | |
| #"Split Column by Delimiter" = Table.SplitColumn(#"Reordered Columns", "Name", Splitter.SplitTextByDelimiter("|", QuoteStyle.Csv), List.Transform({1..Table.RowCount(ConvertToTable)}, each "Level "&Text.From(_))), | |
| #"Merged Queries" = Table.NestedJoin(#"Split Column by Delimiter",{"NodeKey", "FirstParentKey"},ParChTable ,{ChildKey, ParentKey},"Split Column by Delimiter",JoinKind.LeftOuter), | |
| #"Expanded Split Column by Delimiter" = Table.ExpandTableColumn(#"Merged Queries", "Split Column by Delimiter", List.Difference(Table.ColumnNames(ParChTable), Table.ColumnNames(#"Replaced Value1"))), | |
| Rename = Table.RenameColumns(#"Expanded Split Column by Delimiter",{{"Level", "HierarchyDepth"}}), | |
| Parents = List.Buffer(Rename[FirstParentKey]), | |
| IsLeaf = Table.AddColumn(Rename, "IsLeaf", each not List.Contains(Parents, [NodeKey])), | |
| NoOfInterations = List.Count(fnAllParents), | |
| LastIteration = Table.SelectRows(ExpandLG, each ([Level] = NoOfInterations)), | |
| EndlessLoops = LastIteration[EndlessLoop], | |
| IsEndlessLoop = EndlessLoops{0}, | |
| RemainingResults = Table.NestedJoin(IsLeaf, {ChildKey}, LastIteration, {ChildKey}, "x", JoinKind.LeftAnti), | |
| Custom1 = if IsEndlessLoop then [Message= "The data is in an endless loop. Check Table in ""Endless Loop""", #" Endless Loop"= LastIteration] meta [ResultsSoFar = RemainingResults] else IsLeaf | |
| in | |
| Custom1 | |
| ///* | |
| , documentation = [ | |
| Documentation.Name = " Table.SolveParentChild | |
| ", Documentation.Description = " Creates columns for all parents, multiple parents are supported | |
| " , Documentation.LongDescription = " Creates columns for all parents, multiple parents are supported | |
| ", Documentation.Category = " Table | |
| ", Documentation.Version = " 2.0: Checking for endless loops | |
| ", Documentation.Source = " local | |
| ", Documentation.Author = " Imke Feldmann: www.TheBIccountant.com | |
| ", Documentation.Examples = {[Description = " See: http://wp.me/p6lgsG-sl for more details | |
| " , Code = " | |
| ", Result = " | |
| "]}] | |
| in | |
| Value.ReplaceType(func, Value.ReplaceMetadata(Value.Type(func), documentation)) | |
| //*/ |
How to apply
You can also download the pbix-file, where this function in implemented and there’s also a query which enables you to follow-along the results of every step:
DynamicPCHierarchy.zipEdit 2017-May-28: New files for download correcting error in “IsLeaf” (thx to FrankT in comments)
Edit 2017-Dec-2: The code is reworked completely to improve performance. It is now able to handle wide tables as well.
Enjoy & stay queryious 😉
Thanks Imke. What are you using for code formatting? Does it have intellisense or just formatting?
No IntelliSense yet, I’m using Notepad++ with this language code: https://www.mattmasson.com/2015/07/m-language-file-for-wordpress-crayon-syntax-highlighter/
You’ll also find a more advanced approach here, but with some hurdles meanwhile: http://ssbi-blog.de/technical-topics-english/creating-an-editor-for-power-query-with-notepad/
Hi Imke
I have been looking for something like this. I’ve tried to use it by copy-paste the code, but I get error when calling the function. The error provided is something along the lines of:
Expression.Error: Column ‘1190’ in the table was not found.
1190 is the value in the child column. I have tried both with Number and Text. The error is consistent on every line.
I am using power query in Excel.
Any idea what triggered this?
Thanks and regards
Nikolaj
Hi Nikolaj,
this looks as if you’re trying to call the function in an “Add-column”-s step. Then the reference to the column would actually not return a reference to a whole column, but just a record field. That would explain the error message.
Pls check out my sample-file: There step “Custom1” looks like this: = fnFlattenPCHierarchy(Source, “NodeKey”, “ParentKey”, “Name”)
There the function is called “naked” and not within an “Table.AddColumn”-frame.
Pls let me know if this was the reason.
Thx & kind regards, Imke
Hi Imke, thanks for reply. You were right on the money! 🙂
Thanks for the response Nikolaj, glad it worked.
May I ask for which kind of task your are using this technique?
Hi Imke,
thanks for this nice piece of code. I really enjoyed going through your formulas.
I guess, you agree that leaves are nodes that are not parents of any other node. Thus, for instance Julie is a leaf!
Therefore, I have replaced this slip of the pen
= Table.AddColumn(HierarchyDepth, “IsLeaf”, each if [HierarchyDepth]=MaxBrowseDepth then true else false)
with
= Table.AddColumn(HierarchyDepth, “IsLeaf”, each not List.Contains(HierarchyDepth[ParentKey], [NodeKey]))
Hi Frank,
that’s correct – thank you!
Hi FrankT,
Are You sure about this formula? When I replace Imke’s code with your part I get expresion error “Cannot find column [ParentKey] in table”.
I’ve uploaded new files that incorporate Franks corrections – working fine 😉
Thanks again FrankT!
Hi Partnercenter,
I’m very sorry – just recognized that there were still issues with “own” columnnames who caused the trouble. I’ve updated the files again (now also with blanks instead of parent dups).
Pls let me know if you still run into trouble with it.
Thx!
Great article, quick question I have a Manager Table with the ChildID and ParentID that is a guid D9665EF3-22D4-E611-80F8-5065F38AF871, there are 10K records, when I run the function it runs up to around 22K and then never finishes. I am wondering if the GUID is breaking the function?
So child and parent have the same id?
Thanks for this Imke. This came in very handy recently as my team had to bypass connecting Power BI to a cube and go straight to the underlying tables in SQL. Question: is there a reason why you have the child levels that dont have children filled in with the parent name, instead of just blank?
Thx David, very pleased to hear!
No reason for that other than following one of the examples from the referenced article. If you want to keep them blank, replace the “PivotTable”-step with this code (much easier actually):
PivotTable = Table.AddColumn(HierarchyPath, “PivotTable”, each Table.AddIndexColumn(Table.FromColumns({[PathItems]}), “Level”,1,1)),
v3 seems to have a bug. A sample of affected HierarchyPaths looks like
1
1|2
2|1|3
2|3|1|4
3|1|2|4
Interestingly, not all branches of the tree exhibit this behavior.
Also, it seems to incorporate the above solution for leaving empty children blank without the way to go back to have the latest child duplicated till the latest level.
Upon some investigation, there’s an assumption, in the ‘PathItems’ step, that the code for each child is greater than the code for any of its parents, so the function breaks for data where this is not true.
sorry, missed your first comment.
Busy currently & will look into this later. Thanks for the hint!!
Yes, you were right, the List.Sort was causing errors, should have been List.Reverse instead. Sorry for that, I’ve updated the code.
I’ve also adjusted the lookup for multiple parents, which was also not working correctly.
Thanks again for reporting this error!
The surprising usefulness of ignorance: might not have bothered to report had I known M enough to fix this for myself 🙂
Is the below a good enough way to make hierarchy non-ragged?
PivotTable = Table.AddColumn(HierarchyPath, “PivotTable”, each
Table.AddIndexColumn(
Table.FromColumns ( {List.Combine ({
[PathItems], List.Repeat( {Record.Field(_,ChildKey)}, MaxBrowseDepth-[HierarchyDepth])
})} )
, “Level”,1,1)
This does look very advanced as it’s heavily nested & unfortunately doesn’t work if I paste it into my code. So would you mind sharing your full code please?
Thanks, got it: The closing bracket was missing:
Table.AddColumn(HierarchyPath, “PivotTable”, each Table.AddIndexColumn( Table.FromColumns ( {List.Combine ({ [PathItems], List.Repeat( {Record.Field(_,ChildKey)}, MaxBrowseDepth-[HierarchyDepth]) })} ) , “Level”,1,1))
Actually, this is very similar to my version from the query “fnFlattenPCHierarchyFollowAlong”:
Table.AddColumn(HierarchyPath, “PivotTable”, each Table.AddIndexColumn( Table.FromColumns ( {List.Union ({ [PathItems], List.Repeat( {List.Last([PathItems])}, MaxBrowseDepth-[HierarchyDepth]+1)})}), “Level”,1,1))
It works, for sure, but I still prefer my compact version:
= Table.AddColumn(HierarchyPath, “PivotTable”, each Table.AddIndexColumn( Table.FromColumns({[PathItems]}), “Level”,1,1))
Were this a Sales Department dimension hierarchy and were there sales directly attributable to managers (technically, not hierarchy leaves), the non-ragged version would seem to appeal more from the ease of joining to the fact table point of view.
Besides function choices, one major difference I see is that you add +1 to the Repeat counter – why?
You mean step “MaxBrowseDepth”? This row is redundant (leftover from a different version that I’ve forgotten to delete). You can ignore or delete it.
Ouch, I missed the comment tree! This was meant to continue the discussion of making the hierarchy non-ragged, and referred to the ‘MaxBrowseDepth-[HierarchyDepth]+1’ part.
Which step in which query do you mean here?
I’m referring to the fnFlattenPCHierarchyFollowAlong query you mentioned a couple of comments back
You mean the step “PivotTable” there?
= Table.AddColumn(HierarchyPath, “PivotTable”, each Table.AddIndexColumn(Table.FromColumns({List.Union({[PathItems], List.Repeat({List.Last([PathItems])}, MaxBrowseDepth-[HierarchyDepth]+1)})}), “Level”,1,1))
Good question! This is due to the non-intuitive but very useful behaviour of List.Union: https://msdn.microsoft.com/en-us/library/mt260726.aspx
This function is supposed to match duplicate values as part of the Union. This will be done in a very special way (this is just my own observation, haven’t seen any official documentation for it yet, so maybe there is actually a different logic behind it): For every element of the first list, it will check if there is a duplicate element in the other list. It will then eliminate the FIRST element of the list and leave the other dups in place. So if you have: List.Union({ {1, 2, 2}, {1, 1, 2} }) = the result will be: {1,2,2,1}. The first 1 of the 2nd list has been matched as a duplicate against the first 1 of the 1st list, but the 2nd 1 remains and stands at the end. The order of the elements is interesting here, as the 1 from the 2nd list comes last. So it seems to take the first list first and then adds all elements from the second list that have not been eliminated as part of the dups-removal.
In our case we are always filling up with dups (taking the last element of list [PathItems]), of which the first one will be removed from the List.Union. Therefore adding one if it to it again (+1).
Hi Imke,
Somewhat new to the code and query side of Power BI. I thought I had it set up correctly, but I’m getting the following error:
Expression.Error: There weren’t enough elements in the enumeration to complete the operation.
My table has about 90K rows of data. Any idea what could be causing this or where to start looking to solve it?
Mike
One possible reason for this error-message is duplicates in your table: The column-selection in the parameters must not have duplicates for this to work.
Where to write Download M-code: Flatten PC Hierarchy M-code
In power BI?????
You use it in Power Query in Excel or the query editor in Power BI.
Paste it into the advanced editor there (this video shows how: https://www.youtube.com/watch?v=S9xlq5KUZ60&t=666s)
Thanks for Help i found Advance editor and it’s work.
Hi, Imke!
I used your function to deploy the company’s organizational structure. I have a staffing table, in which about 12 thousand lines, 30 columns, the maximum nesting of the hierarchy is 7 levels. Performing your function on my data set takes about 15 minutes. What could I have done wrong? Is it possible to speed up the implementation? Is there a Power Query debugger in which we can see the duration of execution of the query elements and the amount of used memory in each of the steps?
I’d recommend take just the columns you need for the parent-child-allocation and then merge back the other (27-ish?) columns after the operation.
Unfortunately currently there is no analysing tool like you’ve mentioned.
Thank you for your help, Imke.
According to your advice after the some necessary transformations of the original table- Tbl1, I used it as the source of the new query Tbl2, left only 3 columns and applied the function. Execution about 3-4 minutes. Then, in a new query, Tbl3 used the Tbl1 as source and added Tbl2 by the key field. Expanding the columns of Table 2 takes about 3-4 minutes. Is it possible to improve such an algorithm for acceleration?
Hi Denis,
very sorry for this slow code – in one the latest update I missed a buffer.
But now I’ve completely reworked it, please test with your data and report back: New Function
It does the split of the vital columns automatically, so you just have to feed in your original table here.
Thanks and cheers, Imke
Imke, this is a great solution. Works 2-4 times faster. Thank you so much!
P.S. for universality, it is better to remove the hard binding to the column names. Not in all places of the code used function arguments.
1.SLICER/FILTER FOR PART VERSION,CHILD PART VERSION,PARENT PART NUMBER
2 SLICER FOR PARENT PART NUMBER – UNIQUE & MATRIX TABLE FOR LEVEL
3.IF I SELECT ANY PARENT PART NUMBER IT SHOULD SHOW LOWER LEVEL CHILD PART NUMBER ONLY
In the Power Bi Project for this, what Matrix are you using? Is that a regular matrix or a 3rd party?
Hi Michael,
you mean the matrix visual? It’s just a standard with Matrix style set to “Condensed”.
Cheers, Imke
Ah, Ok. But how do you get Level 2 and Level 3 to appear without the drill down? If I drop a Matrix next to yours and add the same level 1 hierarchy and depth fields, I only see Level 1 and have to drill to see 2 and 3. Is there a setting in the matrix somewhere to see all of the levels at the same time without drilling?
OK, now I see what you mean. I have no idea: Seems that this is an old visual and the features have changed. I’m also not able to re-create my visual from scratch and it is not highlighted in the selections.
Sorry about that.
Hi Imke,
Thanks for the post. I’ve tested this on my test data consisting of 10 records,worked fine and I was able to do things which I wasn’t able to do through DAX path function.
However, when I apply this on my actual data of 2.6k records, invoking of the function were not completed after a couple of hours.
I’ve checked there are no duplicates in my records and I am working on 4 columns table.
I’ve used ChildKey, ParentKey and Employee Name as parameters.
What could be the reason for this is taking so long and unable to create an hierarchy?
Sorry, just updated the improvements in the blogpost.
Please download again and test, my 50k rows returned in less than a minute.
I’ve downloaded it again and loaded my table in your PBI Report file. Received the following error:
An error occurred in the ‘’ query. Expression.Error: The column ‘NodeKey’ of the table wasn’t found.
Details:
NodeKey
Later, I changed my field names to NodeKey, Name and ParentKey and called the query
This time it returned an empty table.
What do I do wrong? Can you help me, please?
Thanks.
Thanks for heads up! Uploaded the correct files now.
Thanks for correcting Imke.
I don’t know why but I have two fields in my table and those are the Child and
the Parent Keys in number format, 2.6k rows, but it takes too long to execute the query. It took whole night to execure using the previous version. This version seems to be faster but again for now already half an hour past but no result! Right bottom of the screen, I see the data size goes over 100GB!
In my table every child has only one parent. This is an employee hierarchy in an organisation. Would a change in the script help me to load it quicker?
Hi Imke,
I’ve checked the most recent zip file but there is no pbix file inside.
With the latest version of the query, I received an error like there is no Node_Key for a record.
Using the first query I was able to calculate a hierarchy correctly for that specific record. There may be an issue with the latest query you shared.
Thanks
Hi Imke,
I have 16GB of memory and loading data from a csv file. There are 9-10 levels in the hierarchy. Have the checkbox checked already.
Sorry about the empty file, it should be fine now.
What a pain – I feel sorry for you, but here at my side, everything runs fine. Also the code from GitHub is alright. Make sure that you don’t post it into Notepad ++ or other software, as that might mess up special signs in some cases.
Do you have multiple parents? If yes, how many lines in total will be generated (if there are twisted allocations or loops, that might actually cause problems).
The last idea from my side is to buffer the csv-file after import. Sorry – that really is the last straw here
Hi Imke, i have just downloaded your latest (6) version. The function works great, but i am after the ExplodedName which does not appear to be an output of the function; but it is in the FollowAlong(3) table example. Unfortuntely, i am a total novice to Power Query and am finding it hard to follow along even with the the FollowAlong examples. Also, the FollowAlong example appears to bloat my dataset from 104 rows to 437 rows. Is there a version i’m missing which contains the ExplodedName as an output to the function?
thanks, brent
Hi ,
I download your sample, but it’s not work. I got something error.
Feedback Type:
Frown (Error)
Product Version:
2.56.5023.942 (PBIDesktop) (x64)
Error Message:
: (New) NodeKey, (New) FirstParentKey, (New) FirstName, (New) Path, (New) Level, (New) Level 1, (New) Level 2, (New) Level 3
Hi James,
sorry, the visuals haven’t been connected to the new queries. That’s fixed in the new file now.
Cheers, Imke
Will this work in Direct Query? I got the function to work, but when I hit APPLY, I get this error “Failed to save modification to the server.” I can’t make any modifications to the server because it’s hosted by Microsoft and they won’t allow it (I’m connected to a Dynamics 365 FO elastic pool). I tried disabling the enable load, but then it just hides the query.
Unfortunately there are limitations in Direct-Query mode: https://docs.microsoft.com/en-us/power-bi/desktop-use-directquery , one of them being “If the Query Editor query is overly complex, an error will occur.”
This seems to be the case for this query unfortunately. So you’d have to import instead.
Hi, complete newbie here!!..Do you have an excel file with this function already set up in power query? Struggling to follow the steps
Thanks
You can simply copy the query from the PBI-file to Power Query in Excel.
I have a large data set having 25 000 000 rows. Above function is taking so much time to compute. Is there any other way around?
This function might be a bit faster: https://www.thebiccountant.com/2017/05/08/dynamic-bill-of-material-bom-solution-in-excel-and-powerbi/
But 25 Mio rows might actually be a bit too much for such an approach in Power Query.
Sorry,
Imke
I have about 20k rows and yet the function keeps on going for ever. Been running for a couple of hours now, still not done. Can I assume this is not how long it should take on this number of rows? Any way of debugging it and see where it might go wrong?
Pingback: Parent-Child Hierarchies with multiple parents in Power BI with Power Query
Hi! Im having the same problem… it keeps “evaluating” for ever… and i’m doing a test just with 18 rows. Do you know what could it be? It doesn’t show any error, it just stays “thinking” ;p
Hi Martin,
this will happen if you have a circle in the parent-child-items. This will create a never ending loop.
Say A is parent to B in the first row and B is parent to A in the second row.
You can check this if you create a sorted list of those 2 column values and check for duplicates.
Add a column with List.Sort({[ParentColumnName], [ChildColumnName]}, Order.Ascending), check it and keep duplicates.
/Imke
Hi Imke,
Firstly I just wanted to say how incredibly helpful this code is and thank you very much for sharing.
I do have one question though. My input table has some additional columns that I use in the Power BI hierarchy visual to do some conditional formatting. However, the function seems to set the values of these columns to null for level 1 (i.e. where parent is null) only. For all other levels it populates them from the source table. Is that the expected behavior? If so, is there any way to change it?
Thanks,
Mark
Hi Mark,
not exactly sure what you’re looking for.
Could you please paste link to to a sample file that describes the desired outcome?
Thanks and kind regards,
Imke
Hi Imke, I like and use your code a lot. Thanks for sharing, because I would have never be able to do this by myself. I’m struggling with one thing however: I need to have the total quantity of a part or assembly in the overall BOM.So quantity needs to follow the path and multiplies if on some level quality >1. How to do this?
Hello Ruud,
please check out this article: https://www.thebiccountant.com/2017/06/13/bill-of-material-bom-explosion-part2-costing-in-excel-and-powerbi/
/Imke
Mine is still loading after 16 hours – with 400k rows. Do you think there must be an issue like duplicates etc. or is this behaviour as expected..?
Is the data modell and/or other tables influencing this or is the focus only on this single table?
Hi tbones,
You might be in an endless loop here. This would happen if you have a combination where 2 (or more) items are both in a parent-child as well as in child-parent relationship to each other.
I will adjust the code to cater for this.
/Imke
thank you for the very quick reply Imke! 🙂
I am not expecting an adapted code soon (it is weekend) 🙂 but how long will it take..?
Or how may I check this on my own?
Thank you so much. It is such a great work!!
Well, weekend is when I have time for tasks like this 😉
Have just uploaded the new code.
/Imke
sounds passionate. 🙂
thank you so much Imke!
I am trying to run the new code and have two questions:
Not having any M code skills makes me wonder how to follow the described step from above “add a new step to your current table where you call this function, filling in the following parameters:” Even the screenshot is not clear for me 🙁 I used the function in the PBIX before (copied it), but the current code is not included in the linked file, right? Is it possible for you to update?
After using the function in another table with similiar amount of data for testing, it went through in about 20-30 min. It also needs the same amount of time for every refresh, when working with the tables. Is there a way to speed up or would you suggest to deactivate refresh for this function?
Hi tbones,
sorry to hear that you’re still having problems.
There was actually a small glitch in the last function – so please use the newest one if you try again.
I’ve uploaded a video on how to use this function here: https://youtu.be/vjfeZojshxQ
Hope this helps,
cheers Imke
Hi Imke, Brilliant code which has meant I can now have my current org structure in a dataflow and use in multiple other reports.
One issue I have had is the top level manager (MD) has had all the information from their row removed and replaced with blanks. Is there a tweak I can do to the code to rectify this?
Many thanks
Rob
Hi Imke, brilliant Code, thank you. I will need to settle in and give it a good session to see how you have coded it.Let me tell you how I am using and see if you are able to help me with the final issue I have. We have considerable workflows designed in BPMN format, these workflows are exportable in XML.I clean up the format and identify the sequence of events e.g. which task precedes which task. Using your code this allows me do determine all the paths through the workflow and also with some DAX applied (yet to do) determine critical path time and average lead-times for tasks. There is one issue I am facing, and that is the handling of endless loops. In a workflow you do get the situation where a task will loop back onto itself, I am wondering if it is possible to allow the endless loop however only once to allow the output to show that this is a possible path. If you need more information to show what I am trying to achieve I am happy to share.
Regards
Mike
Hi Mike,
yes, I need more information here, as I don’t understand the requirement yet.
Please post link to a file with some sample data with the exact desired output.
Regards,
Imke
Hi Imke, see attached 2 files.
PBIX: https://1drv.ms/u/s!Anqm7JJxFN696XFHYvWHqBzeu–a?e=jRxquM
Work Flow: https://1drv.ms/u/s!Anqm7JJxFN696W9aDDpx0mRoSk-g?e=rbfIIx
If you look at the Workflow you will see a highlighted area, this is the part where the endless loop occurs. The way I have set it up is that the predecessor task is the Parent and the following task is the Child. You can see that the task “SAED PM Confirms Final SPO Issued to Supplier” can eiter move forward towards the end of the Work Flow or depending on the condition go to the task “CPM Revises VOA Details”. If it goes through this latter task it then goes to “SAED PM Confirms Final SPO Issued to Supplier” hence it will get stuck in an endless loop. If you look at the Dependency path in the PBIX file you will notice that all possible paths through the Work Flow have been mapped (I have removed the Endless Loop creating task to give you an example of what it would look like). Ideally where there are endless loops like this it will perform it once and show the path through the loop. In this case the path would be, starting at the “SAED PM Confirms Final SPO Issued to Supplier” task as follows:
“SAED PM Confirms Final SPO Issued to Supplier”|”Gateway”|”CPM Revises VOA Details”|”SAED PM Confirms Final SPO Issued to Supplier”|”Gateway”|Gateway”|”End of WF” (this last one is the circle at the end). This shows it going around the endless loop once and then continuing on after the first time.
I know this isn’t how you would normally use the code, however a rather novel application of it. If there is nothing possible thats fine just let me know and I will search for other alternatives to my problem.
The purpose behind this exercise is that we have 50 + of these work flows, some with 100+ tasks in them, when it comes to determining lead-times between tasks and critical path on averages it can be extremely time consuming. I see this as a way of automating the process for our organisation.
Thanks
Mike
Hi Imke,
Your code helped me ! I have a new problem with a hierarchy parents children. Unfortunately, I obtain loops in the table result and cannot use it.
I would like to know if it is possible to calculate all lines which are correct and just ‘forget” with a blank result when we are in a loop. The problem I have is I cannot change data because they are provided by Human Resources dept. so I just have to manage them.
Now, 6 lines are in a loop on 100000 so it will really nice if it can works for 99994 😉
Another question, is it possible to just have the columns calculated by your code and not add all other columns from the original table. It will increase the size of my database
Thank you in advance for your great help
Hi
This works just fine except for that i get “Unknown TopLevel xxx” each row in Level 1. Don´t understand what i have done wrong, any ideés?
Thanks, Imke. This functions works on most lines but if a parent-child relationship repeats more than once the function creates a large number of records. For example, I have 4 records with the same parent-child relationship and 64 records were created after I ran the function.
Pingback: Power BI Field Finder -
Thank you Imke for sharing this code.
Just a small question,
During dataset refresh in UI, my hierarchy table does not import new data.
It is refreshing properly in the Power BI desktop.
Any suggestions why it is happening?
Please advise how to resolve the blank situation, i do want to see the data at the top level.
Hello,
Excellent solution for those who want to use a dynamic hierarchy. In this case I’m using a Dynamics CRM hierarchy and it works perfectly. Recently almost all rows started to duplicated, I went from 30k rows to 340k. I had to insert a Step to Remove Duplicates. Now to load the 30k rows without duplicates it takes almost 2hours. Any solution in sight?
Hi Flavio,
unfortunately I’m not able to replicate.
Could it be that you have duplicates in your source data already that would cause this issue?
/Imke
You’re right, it was a problem with my data. works perfect
Hi Imke,
Thanks for this query, I have not found a solution to this anywhere else and yours is so close to what I need its almost perfect for me.
Is it possible to do this in reverse? I have three columns. Parent, Child, Cost Centre. I want to find all the children of each parent until the lowest level where there will be no parents.
Regards
Hi Adam,
this is a very old function, not sure if it works correctly, but you might want to try it out:
let func =
(ParChTable as table, ChildKey as text, ParentKey as text, DescriptionField as text) as table =>
let
// Parameters for Testing
// ParChTable = Employee,
// ChildKey = “EmployeeKey”,
// ParentKey = “ParentKey”,
// DescriptionField = “Name”,
in
AllChildrenJustLevel0
, documentation = [
Documentation.Name = ” PCH_AllChildren
“, Documentation.Description = ” Parent-Child Hierarchy: Show all children and associated data like level, indent
” , Documentation.LongDescription = ” Parent-Child Hierarchy: Show all children and associated data like level, indent
“, Documentation.Category = ” Parent-Child Hierarchy
“, Documentation.Source = ” local
“, Documentation.Author = ” Imke Feldmann @TheBIccountant
“, Documentation.Examples = {[Description = ”
” , Code = ” öalsdfk
“, Result = ” adsfö
“]}]
in
Value.ReplaceType(func, Value.ReplaceMetadata(Value.Type(func), documentation))
Hi Imke,
Thank you for the code. It works really well in PBI desktop.
I have to use it in dataflows, and I get the following message: “The query “Query1″ returns an output that is non-trivial. Simplify your output step, or let Power Query simplify it for you.”
When I let Power Query simplify it, it still doesn’t work correctly. The issue is, that I don’t get the dropdown for ParChTable – it’s just greyed out and it says “null”.
Is there a soloution for this?
Thanks!
Regards,
Loam
Hi Loam,
very sorry to hear about it. Unfortuntely I don’t have the time currently to rework this function.
Sorry, Imke
Hello Imke,
Great piece of code! Kudos!
I have one issue though, the function does not ignore the filtered rows from the reference table and calculate them also.
Is there any way that the function ignores filters rows??
Thanks in advance
Hi- Great piece of code.
couple of questions – rather claririfactions
1) It seems the function is dropping the original parent key, Child key and the LevelName columns supplied as parameters? – I’d expect the right think to do is to Preserve the original table-columns and append new columns.
2) Based on the comments posted, and your response, there appears to be v3 version? however the link you provided to the code show teh documentation as v2? Double-checking if the right version is linked here.
Again- Great work and thank you
I cannot understands, what the Node column should be. I have only Parent & Child Columns and if I copy Child Columns as node, I get Level-1 as unknown Toplevel for some rows.
I have exactly the same issue. Is there a solution for that?
Pingback: SAP BW (parent/child) hierarchies in Power BI - Cubis
Hello Imke,
Thanks for your brilliant work!
Wanted to ask if there’s any well-known cause for the function to fail splitting the path (not for all all entries, only specific ones) to levelN columns, it just puts all the node names path into Level1 column with “|” delimiters.
Struggling to find the issue, but without any progress so far
Thanks!!! But I’m still facing a problem…
In my Matrix, the Level1 is being shown again when I expand. So the value is being sum twice…
Category A 20,000
10,000
Subcategory B 5,000
Subcategory C 5,000
The blank row is the Category A value where the level2 info is null (root). So the category A must show the value 10,000 but is showing 20,000 instead. How can I solve this? Please!
I think there’s an error in step RemainingResults. It refers to the argument ChildKey, but in step ExpandLG, the column that that argument relates to is expanded with the name NodeKey.
My Schedule has a vast number of tasks and PBI is taking a tremendous amount of time to run this function. As I write this, it has been running for 30 minutes and still going. Is it right? Is there any way to improve this matter?
Thanks
Just forget about my previous comment, I made a mistake. Sorry about that. The function is perfect.
Hi Rogerio, mine also seems to running for a whole and nothing happening (it seems) – did yours sort it self out or did you have an error?
First love your code sample, thanks so much for sharing and supporting it, I have one modification we require, our data has childId, ParentId and it builds the hierarchy out great, but our data also contains a siblingsortorder column that is used to order the items in each branch. I attempted to try to incorporate but i am breaking the code more than fixing it. My initial thought was to add a SortPath and append it just like path then break it out in the same way as level 1 but as a new column Level 1 Sort, Level 2 Sort etc. but as I said my code is breaking it, do you think you could point me in the right direction for where to tweak the code to add ordering to the hierarchy levels so our Power BI hierarchy comes out correctly. Thanks
Hi all,please help me out in this task
Hi,
This is great and working fine for my scenario. However, I am struggling with the repeated values for blank values in hierarchies. Where we have 17 levels, if one measure got values for few hierarchies out of 17 the last hierarchy value is repeating for remaining blank hierarchies, do you any fix for this? Thanks in advance.
Example:
Hierarchy Amount
Accruals_plus_Outstandings -84224883678
Accruals -29983243889
Outward Premium -4715284971
Ri Premium -13025047246
Blank -13025047246
Blank -13025047246
Blank -13025047246
Blank -13025047246
IN above example, we got values till level 4 and from 5th level onwards it’s repeating the 4th level value until 17.
Unfortunately it looks Imke no longer comments this post, but kean to here if anyone has comments to these high-level options:
1) Should this be done in Power BI or in the database? It will require dynamic SQL to do it in the database if another level comes into the hierarchy, but using the calculation power in the database, might iron out any performance issues?
2) How about alternative hierarchies. Typical example would be Organisation Structure, where there could be a Legal and Management Hierarchy, based on the same lowest level?
I don’t think Power BI supports that option within the same slicer yet, but it would be nice to have it ready when it hopefully comes around.
Hi any idea how to integrate this into hierarchy slicer visual?
hi, how this code scales? i have written much simpler one, but it chokes very quickly and i have no idea why, so i was wondering if you have encountered similar problem. i have 2k members of maximum depth 15 levels.
my looping code:
let
Source = (parChild as text, inpTable as table)=>
let
inputHierarchy = inpTable,
Source = List.Reverse(List.Generate(()=> parChild, each _<>”top”, each inputHierarchy{[nameCode = _]}[parentCode])),
makeTable = Table.FromList(Source)
in
Table.Transpose(makeTable)
in
Source
Hi Imke,
Thank you so much. Works like a charm.
Kind regards
Frank
This works great ! but is very slow when the data is huge and there is level 10 deep hierarchy. Any suggestions on that is very much appreciated !
Hi Imke,
Thank you for this excellent function. Your documentation above says that ‘LevelColumnName’ is the “name of the column who’s values shall be shown in the levels (can also be child-key)”, but the function fails if you make ‘ChildKey’ and ‘LevelColumnName’ the same. So, I have made some minor changes to the early lines of the function as shown below and this now allows you to use the same column for ‘ChildKey’ and ‘LevelColumn’.
Many thanks!
Ian
Here are the first few lines of code that I modified…
let func =
(ParChTable as table,
ChildKey as text,
ParentKey as text,
LevelColumn as text) =>
let
LevelColumnName = "LevelColumnName",
DuplicateLevelColumn = Table.DuplicateColumn(ParChTable, LevelColumn, LevelColumnName),
SelectRelevantColumns = Table.SelectColumns(DuplicateLevelColumn, {ChildKey, ParentKey, LevelColumnName}),
#"Changed Type" = Table.TransformColumnTypes(SelectRelevantColumns ,{{ChildKey, type text}, {ParentKey, type text}}),
…