
Very often I have thought about trying M instead of R for machine learning problems in PowerBI. Not only because I’m such a big fan of M, but also because we don’t have the R-integration in Excel (yet?).
Leila Etaati’s brilliant series of how to use R in PowerBI for KNN-prediction (nearest neighbourhood) finally kicked this off. In order to trigger some thoughts I have structured the code in a way that resembles the R-structure. So the core M-code looks like this:

KNN in M
Where this sits in a function that you feed with the following parameters:
Function Parameters
In there, 2 functions are called, like in the R-code. While the functions already exists in R and you just have to load the necessary packages, in M we don’t have these functions (yet), so I had to build them:
Normalizing the table:

Evaluating the nearest neighbour-label:

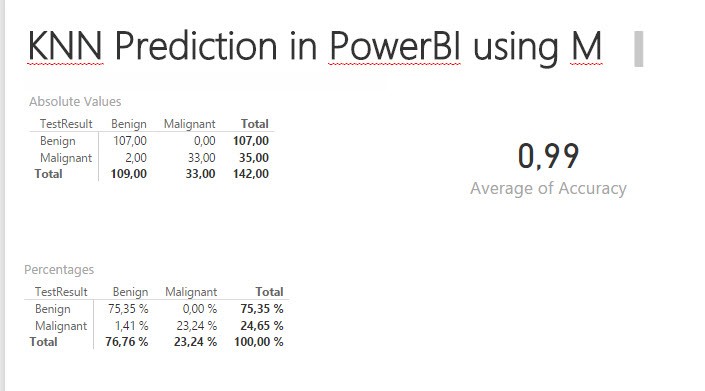
I also added some comfort-features: The k-value will be calculated automatically and you can enter a %-value for the split between training & test-data.
Key-findings:
M has all it needs to calculate the results, but the performance can be a pain. To my understanding so far, this is mainly due to the fact that it will call the sources multiple times. Unlike in SQL-server for example, the execution plan is hidden and we also don’t have stored procedures which enable us to de-activate the re-evaluation of the execution plans with every data refresh.
While I see the point in not re-inventing the wheel, there is an aspect of how many languages we are expecting the PowerBI-users to learn. Just a thought.
File to download:
zipped pbix:
KNNR2-1.zip
Enjoy & stay queryious 🙂
“Very often I have thought about trying M instead of R for machine learning problems in PowerBI. Not only because I’m such a big fan of M, but also because we don’t have the R-integration in Excel (yet?).”
Hi Imke,
It’s very much the same for me. I’ve done K-Means++ in M, but I haven’t yet considered my next challenge. There are some add-ins out there for integrating R and Excel (most are free), but I’d like to see a Microsoft solution.
Hi Colin,
I would have been very surprised if you hadn’t played with that as well 😉
Really hope that we’re going to see R in Power Query / Get & Transform. Within the Excel-community there is a much louder voice for Python-integration. Wouldn’t mind that: Python in Excel and R in PQ/G&T 🙂
It would be great if they implement it in way that will make the separate installation of R & RStudio obsolete.
With the integration of M into SQL vNext a lack of R in PQ would mean quite a big gap in “downward” compatibility also.
Happy Easter, Imke
I’m actually not a fan of the Python stuff, although the idea has gathered enormous support. Getting too old to learn all these new languages:) Better R integration would be great though.
How about making M more universal? For example; 1) as an alternative to DAX (not a replacement). Just provide M with the missing DAX functions (where it makes sense) and have it generate MDX when used in the data model; 2) Extend M to interoperate with the Excel data model, and have it generate JavaScript code (or not) when used in that environment.
As you may have guessed by now, I like dreaming (not to mention M). 🙂
Have a Happy Easter.
Hm – looks like I have to learn what’s under Excels hood, as your suggestions wouldn’t have occurred to me. Can you recommend links here?
1) M as a DAX-alternative: You have me on board here (and not just me) – but why generate MDX and not DAX when used in the (PP?) data model?
2) I’m not accustomed to the Excel data model at all. Is this where the results of an M-query that’s on “Connection only” live? Or is it a 3rd environment? What’s the Java-connection here?
Speaking about dreaming: Top of my list is transparency on what’s killing the performance and a switch/command to stop re-evaluation or previous steps 😉
Cheers, Imke
“but why generate MDX and not DAX when used in the (PP?) data model?”
Because DAX generates MDX code under the hood to communicate with the Analysis Services engine. Therefore, there’s no point adding another layer on top of DAX.
“I’m not accustomed to the Excel data model at all. Is this where the results of an M-query that’s on “Connection only” live? Or is it a 3rd environment? What’s the Java-connection here?”
Actually, M in Excel would be a programming language vs a query language (like DAX is both a query and a programming language). The options to communicate with the Excel Object Model would be: 1) Create a Primary InterOp Assembly (PIA) to communicate between COM and .NET, which M is based on (possibly the same PIA used to interface current .NET languages with the Excel OM would work). 2) Use the JavaScript API. It’s this latter case that you’d have to translate M into JavaScript code. The JavaScript API has limited exposure to the Excel OM.
In either case, M would have to be beefed up considerably. Today, M supports various types, like number, text, table, and so on. With each type, we can perform various operations (e.g. square an number, remove text from a string, add a column to a table and so on). Now we would have to consider new types like Range, Worksheet, Workbook and so on, that perform similar operations to those in the equivalent Excel object. For I/O (e.g. Userform, and various dialogs like File Open, Save As…), we need to add Reactive Functions (see https://en.wikipedia.org/wiki/Functional_reactive_programming, https://gist.github.com/staltz/868e7e9bc2a7b8c1f754 for example).
“…and a switch/command to stop re-evaluation or previous steps.”
Do you mean like a Switch/Case block? If so, that would be useful, but not as necessary as the Switch function in DAX (and recently in Excel). The M if … then … else if … structure is easier to read than nested IF functions in Excel/DAX (no indenting nor parentheses to deal with). Also, instead of evaluating all if statements, it stops at the first statement that evaluates to true.
As a self-confessed custom function junkie, I have created an equivalent Switch function, but don’t really think that it’s necessary.
Top of my dream list is a true Advanced Editor, fuzzy lookups, and Regex capability (or at least some wildcard support). The first two are likely to be addressed this year, but the last may never be addressed. The lack of Regex or wildcards in M is a gross oversight, making M the only ETL language on the planet with no such support. Given that at least 15 Excel functions support the * and ? wildcard characters, how can having zero functions in M that support wildcards be justified, especially given that they would be more useful in M than in Excel?
Thank you Colin for this very valuable insight – very much appreciated!
What I meant with a switch or command to stop re-evaluation of previous steps was referring to the performance issue. The algorithms in M seem to have such a strong focus on folding back commands, that they will accept re-evaluations of already imported data as an acceptable price to pay. But that often doesn’t turn out as the fastest way at the end. So in order to speed up operations, I often find myself “staging”: Loading the first result of an import into a worksheet and import that back (like a linkback table) into M for the transformations. (Splitting the E from T&L) Yes, this means that you need to hit the refresh-button twice, but still – often much faster. (Always disable background refresh)
And of course, the items from your wishlist are on mine as well. 😉
Agree with the performance concerns and the need for transparency on what’s killing performance. I have to deal with inexplicable performance issues with some custom functions, and sadly, I believe that a lot has to do with built-in functions that are not optimized for even medium-sized data sets. For example, this simple expression List.Sort({1..20000}, Number.Random()) is quick to sort the list randomly, but List.Sort({1..200000}, Number.Random()) takes an unacceptable amount of time to sort the list. Come to think of it, many List functions exhibit poor scalability in my view.
One thing I forgot to mention on M and Excel integration was that it originally stemmed from the notion that M would be better for creating user defined functions (UDFs) than VBA.
UDFs: Now we’re entering very promising area – you can count me in on that.