
This is an old post. Meanwhile we can implement proper incremental refresh with Power BI licenses: https://docs.microsoft.com/en-us/power-bi/admin/service-premium-incremental-refresh
Warning – edit 03-Jan-18: This method doesn’t work in the service unfortunately. Please upvote the bugfix here: https://community.powerbi.com/t5/Issues/quot-Include-in-report-refresh-quot-disabling-doesn-t-work-in/idi-p/331982#M19945
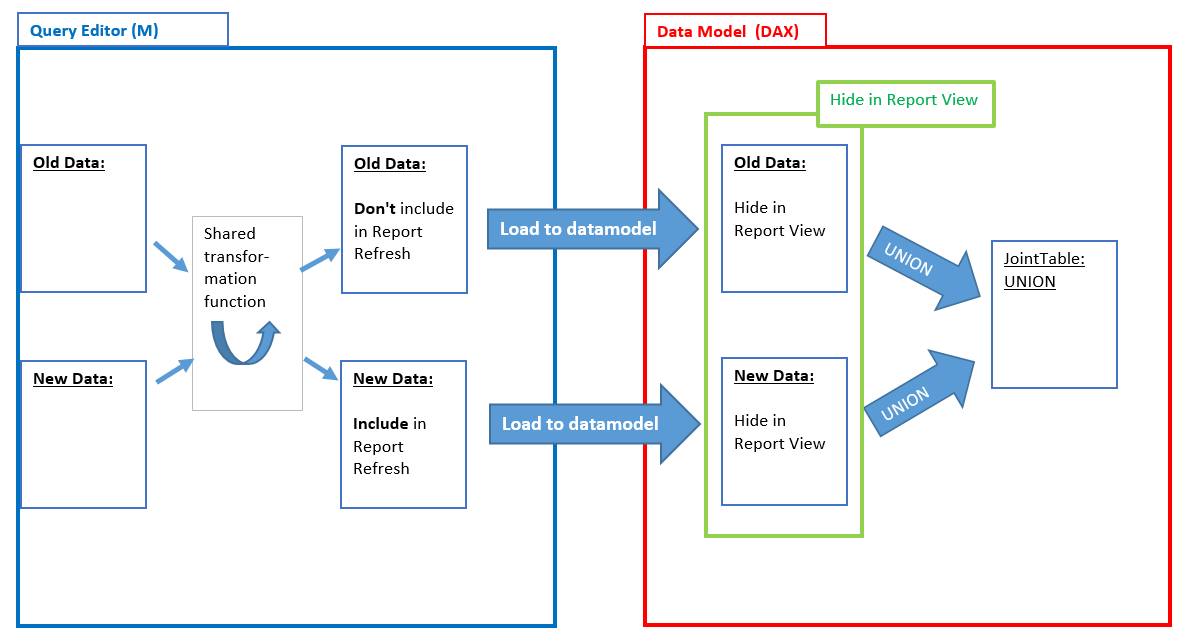
This article describes the latest workaround for incremental load in PBI (thx to Taylor Clark for stressing this out!). It’s not very dynamic, as it doesn’t automatically load the difference to the existing data. Instead you have one query that contains your old data (which will be kept) and another query that grabs all data that comes after the last item from your old data. But at least it’s a technique that works without a hack:

Incremental Load Process
1 Create “Old Data”: “DontRefresh”
So it’s up to you to split up your long table or web-load activities and load your “old” stuff into one query (“DontRefresh”), perform your transformations and then load into the data model once. Then go back to the query-editor and disable the option “Include in Report Refresh”.
2 Create “New Data”: “Refresh”
Then take the cut-off-filter-criterium and use it to define the load of the new data that will subsequently be refreshed (“Refresh”). Transform your transformations from the first query into a function to make sure both tables have the same structure and load it to the data model (leaving the default load options to refresh).
3 Create table using UNION in DAX
In the data model, you create a new table that appends both tables to each other (and hide both input-tables from client view):

Create table in DAX using UNION
Another reason why this is not ideal is that fact that you cannot perform data transformations in the query-editor that iterate over the whole table. So I really hope that incremental load will once be a native functionality in PBI. Please vote for it here, as Microsoft prioritizes many of its activities on customer feedback: I vote for incremental load
Just picked up a useful tip from Mimoune Djouallah, to use a syntax like this:
union (summarize(table_current, field1,field2),summarize(table_history,field1,fiel
Which highlights the difference between the Append-command from M and the Union from DAX: The Union function requires the columns to have the same order in your table.
4 Why not use Append in the query-editor instead?
Another drawback of the current implementation is a somewhat unintuitive behaviour of queries which have been set to “Don’t include in Report Refresh”: As a standalone-query, they will behave as expected and not refresh. But once you reference them by a separate query or within an append-operation, they will refresh their results. So beware of this potential trap!:

Unexpected Behaviour Warning
Link to file:
csv-sample data: https://www.dropbox.com/s/fovsg2xzclfqrzh/ImportData.csv?dl=0
So don’t forget to vote and stay queryious 😉
I like this idea however it bloats the size of the Power BI data model so could be an issue if the tables get larger. I’m wondering if there is a way to achieve the same thing in Power Query (M) using smart logic around filter settings.
Thank you Phil!
Yes, good point – it doubles the data. Another reason to vote 😉
Actually this behaviour in the query editor just got accepted as a bug, so maybe we can “shift” this workaround to M pretty soon 🙂
http://community.powerbi.com/t5/Issues/Bug-in-quot-Don-t-include-in-Report-Refresh-quot/idc-p/112237#M1627
Imke
SSAS already support table partitions, the SSAS engine in PowerBI support only one partition per table, so I would say it is a deliberate decision per Microsoft, they can easily have an options in PowerBI desktop to say load result to table 1, partition 1,2 etc
Yes, good point!
But I refuse to draw the same conclusions 😉
Please consider to add a hyperlink in the sample files whether it be Excel or Power BI Desktop, then readers can get access to the related blogs immediately.
Hi Julian,
please help me here: Which related blogs do you mean?
Almost each of your blog has a sample file can be downloaded, I meant if you could add a hyperlink in each file then it is very easy for users to get back to your blogs.
That’s a good idea – thank you for the suggestion !
You can check it out in the updated file above 🙂
yes, I saw it, but I don’t know why the hyperlink is not clickable. I’ve addressed this issue to Power BI forum.
Thank you 🙂
Yes, it’s a bit strange: When I click on the link a pop-up-window opens that shows the link again. When I click the link in there, the link will work.
In my case the “hyperlink” seems just a plain text and not clickable.
That’s a pity – maybe it’s also dependent on the browser…
Pingback: Incremental load in PowerBI – The BIccountant
Believe it or not, I struggled many times both on Power BI Desktop and Power BI Service but failed, However with the new version 2.42.4611.701 I just updated hours ago, it works smoothly now.
Hey,
I have spend some time testing this, maybe I have misunderstood the function.
The function I get, is that that the “first” / “old data” remains, and the new data is updated with every refresh?
The function I am looking for is that the new data are added to the old data upon each refresh.
I want to take at snapshot of, for example the stock balance from a SQL like this:
Refresh 1 date: 1-17-2017 time: 08:00
product / bal / date&time
car / 2 / 1-17-2017 08:00
Refresh 2 date: 1-18-2017 time: 08:00
product / bal / date&time
car / 2 / 1-17-2017 08:00 (this line is from the first refresh, and are no longer in the SQL at the time of the second refresh)
car / 4 / 1-18-2017 08:00
I this possible with the function you are describing on this site ?
Hi Ole,
you’re right – this is not the right function for your use case. This would be used to speed up load only (like bookkeeping-data from previous years in the first and then only the current year/month in the new data. One would then need to shift the cut-off-date from time to time, re-loading the old data up to a newer date in quieter periods)
Your request could be handled with export/append to csv-files using an R-script (then you could trigger the refresh directly from the PBI-desktop, like described here: http://www.thebiccountant.com/2015/12/28/how-to-export-data-from-power-bi-and-power-query/ )
Or you use a Powershell-script (like described here: https://github.com/djouallah/PowerBI_Desktop_ETL ) where you could also add a task-scheduler.
Hello,
thanks a lot for your answer!
Im using the “On-premises data gateway”, and want to keep ass much as possible running without any files stored locally.
As I understand the tow mentioned solutions, these requires a server / PC, and the files and scripting will be handled locally, right ?
Im guessing there is no solution at the moment that meets my wishes.
I think im going to create a aditonal table on the SQL server and accumulate the rows there.
thanks a lot for your quick reply.
best regards – os
Yes, these workarounds presented here are to cover typical “self-service-scenarios”, where one doesn’t have access to SQL-server-resources.
If I had access to SQL in the case you’ve described, I’d go the SQL-server-way as well.
So I hope you’ve given your vote to the incremental load 🙂
BTW: If you would be willing to pay for a Pro-Version, that comes with this feature, – please give your vote here as well: https://ideas.powerbi.com/forums/265200-power-bi-ideas/suggestions/17636668-paid-power-bi-desktop-pro
Hi, Can you provide the csv for the soulution?
yes, have a included the link in the article above
Hi! Thanky you for this post. But it seems to me, that it doesn’t work with scheduled dataset updates on app.powerbi.com.
Even if I click ‘update” button there (in web, I mean), dataset starts its fully update, ignoring preset “Include in report refresh = false” option in dataset query.
Maybe I’ve done something wrong?
Haven’t tried it in the service – possible that it doesn’t work there. Sorry.
Hello Imke,
Is this still the best option for PBI free users?
Regards,
André P.
To my knowledge yes, I’m afraid.
Yikes. Just one question: is it possible to implement this when the query that has the new data only has 50 rows (it’s a web service call that fetches the last 50 played songs)?
The historical data query would retain every different one, and not only the 50 records that get updated every hour.
Hi! Would it possible to combine old data and new data using dax if old data is import and new data is direct query?
Many thank
Regards,
ramon
Hi Ramon,
never tried that. Would be great if you try it out and leave feedback here 🙂
Thanks, Imke
I actually tried and new data in direct query didn´t refresh in the dax union but I wanted to know if I was doing something wrong 🙂
I am trying to find other solutions…
Maybe this solution with dataflows is an alternative for you: http://excel-inside.pro/blog/2019/03/21/classical-incremental-refresh-for-cloud-data-sources-in-power-bi-service-for-pro-accounts/
Thank you, but I dont think so… I need DirectQuery to get almost realtime from accounting system but if I use DirectQuery to old and new data the performance is not very good
Hi Imke,
Is it viable to implement this in a Bridge Table?
My Use Case:
Old Sales (non refreshable) + CurrentYearSales (refreshable) = FACT_AllSales, implementing this workaround so it doesn’t make a lot of requests to the API server everytime.
DIM_SalesDocs that is N:N to Sales, so I created a Bridge Table with unique values on Key, from OldSales, CurrentYearSales and SalesDocs.
When Bridge gets refreshed it requests all pages from FACT_OldSales, what makes it a problem again.
So i thought about creating the Bridge using the same workaround.
What can you tell me about this?
Hi André,
never tried such a thing and not sure I understand correctly.
So you will have to try it out.
/Imke
I’ve done it, and apparently it is working. Thanks for answering!
Just for clarification: Bridge_SalesDocs has unique docKeys from DIM_SalesDocs, FACT_OldSales and FACT_CurrentYearSales
When I refresh the Bridge it only refreshes the docKey for DIM_SalesDocs and FACT_CurrentYearSales, as FACT_OldSales docKeys won’t change.
Thanks for clarification!
Hi Imke – Thanks for sharing – I was getting caught in the append trap forcing refreshes on the don’t ‘include in report refresh’ queries. I just wanted to add to the conversation that this technique does NOT work in Power BI Report Server. Even with the report saved with the refresh checkbox cleared – it still refreshes the data. Quite disappointing…