
There might be occasions where you want to import data from Excel into Power Query or Power BI using cell coordinates like a range from E3 until G9 for example (“A1 cell reference style”). The function I provide below also caters for the potential pitfalls of this task that Maxim Zelensky has described in his article.
Background
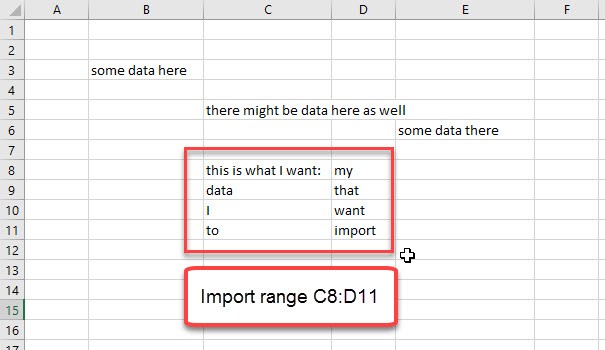
If your worksheet has one leading empty row and column, the import will ignore them and automatically return the range starting from B2. So to fetch the range E3:G9 you have to delete the first row and the first 3 columns. But as Maxim has found out, remaining formats on empty cells will lead to an import of empty rows and columns. So the number of rows and columns to delete will vary and is hard/impossible to predict.
Method
The range that PowerQuery or PowerBI will import is stored in the Excel-file already in the sheet-data and the xml looks like this (“Sample3” from Maxims data):

The imported range is E1 till J12, as the first rows contain formatting instructions, and will therefore be imported as well. In the 3rd row E3 shows up with the first value, which is surrounded by “<v>”.
This is how it looks like in the Xml.Table in the query editor:

Task is to calculate the number of rows and columns delete, considering the individual offset that is caused by the formatted empty cells.
Code
So I’ve cooked together these ingredients in a pretty massive code that you can download here: fnImportFromExcelCellCoordinates.txt
How to use the function
After you’ve copied and pasted the code into a new query in the advanced editor, you can invoke the function and have to fill in the following parameters:

Or watch the short screencast to see it in action:
Limitations
You cannot import a range starting in a cell that’s not within the imported range: This code will only delete leading rows and columns. So the code will currently fail if the entered coordinates are without this range. Please leave a comment if you need that & I will adjust the code.
Useful links
- Unzip your Excel-file with M by Mark White
- Explore your Excel file-structure in Windows Explorer by Professor Excel
Enjoy & stay queryious 😉
Hi Imke! Very nice code inside, with cool insights for me.
I’d suggest to use a ‘dimension’ parameter from sheetN.xml, then you can get top-left (also as bottom-right) cell coordinates, compare it to the function arguments and cut (or add) rows/columns from Excel.Workbook [Data] table. So you do not need to dig into ‘rows’
What do you think?
Yes Maxim, you’re right: The code could have been a bit simpler.
It contains the logic to automatically import without leading “empty” rows & columns, but during programming I decided to change the scope to import with coordinates. At that stage I should have simplified the logic, but forgot about it.
Good spot!
With an optional StartCell (if blank FirstNonEmptyCell) digging into rows is not redundant anymore. Text.Upper(Coordinates) might be reasonable.
@Imke – It is best to ask Excel to derive the Row-Column Co-ordinates
Then you can do this with far less code
Have a look at the file
https://1drv.ms/f/s!AiKBTsYfZw-vgo1nVDYnx8rGRvPxHA
or
———————————————————————————————————
Define a Query : Data
let
Source = Excel.Workbook(File.Contents(fGetCellVal(“fPath”)), null, true),
mData = Source{[Item=fGetCellVal(“fTblNm”),Kind=”Sheet”]}[Data],
mSelRows = Table.Range(mData,fGetCellVal(“StartRow”)-1,fGetCellVal(“EndRow”)-fGetCellVal(“StartRow”)+1),
mSelCols = Table.SelectColumns(mSelRows,Cols)
in
mSelCols
—————————————————————————————————
Define a function fGetCellVal
let
fGetCellVal=(tbl, optional row as number, optional col as text)=>
let
NoOfRows = try Table.RowCount(tbl) otherwise -1,
Source = if NoOfRows = -1 then Excel.CurrentWorkbook(){[Name=tbl]}[Content] else tbl,
rNo = if row = null then 0 else row,
col = if col = null then Record.FieldNames(Source{0}){0} else col,
Value = Record.Field(Source{rNo},col)
in
Value
in
fGetCellVal
—————————————————————————————————————–
Define a List Query : Cols
let
Source = List.Transform({fGetCellVal(“StartCol”)..fGetCellVal(“EndCol”)}, each “Column”&Text.From(_))
in
Source
——————————————————————————————————————–
Hi Sam,
thanks for the code. On my machine, it threw Errors: “Operation is not valid due to the current state of the object”. After some digging I found out that this was due to the string “col”. After I’ve replaced it with “cole” the code worked. I suspect that “col” is kind of a system-reserved string that can cause errors like this on machines with different locales. (Experienced sth similar with “document”)
But it doesn’t return the desired result. Try switching to “Sheet3” of your sample data: It says that “Column5” wasn’t found. That’s because the import will ignore the leading empty rows and columns. You might want to read Maxim’s article that I have referenced above to get some background information about this behaviour. There you will also find the reason why I’ve chosen so address the “Range” from the metadata.
BTW: Nice find with the syntax-sugar of the named ranges. Is there any documentation about this?
Cheers, Imke
@Imke – Could never have guessed that Cols is a reserved name in some locales – do you know if MS has published a list of reserved names somewhere
Also took care of the problem on Sheet3 – with the below modification but I realize that my code would run in to issues in other scenarios – like the ones described on sheet4 and sheet5. (have updated the files on the onedrive)
You code is more robust and I now appreciate its complexity
let
Source = Excel.Workbook(File.Contents(fGetCellVal(“fPath”)), null, null),
mData = Source{[Name=fGetCellVal(“fTblNm”)]}[Data],
mRngData = if Table.RowCount(mData) = fGetCellVal(“EndRow”)-fGetCellVal(“StartRow”)+1 and Table.ColumnCount(mData) = fGetCellVal(“EndCol”)-fGetCellVal(“StartCol”)+1 then mData else Table.SelectColumns(Table.Range(mData,fGetCellVal(“StartRow”)-1,fGetCellVal(“EndRow”)-fGetCellVal(“StartRow”)+1),ColsReq)
in
mRngData
Sam
Thank you Sam!
I’m not aware of a list of that kind.
Hello, first of all, thank you for this amazing function!
I am trying to merge all the .xlsx files in a folder, and before applying your function what I have is a column with the file name, another with the folder path, another with the sheet name (there are many sheets to consolidate in each file) and a Data column with all the data of each file.
I am trying to use your function, taking the FullFilePath from my “folder path” column, the SheetName from my “File Name” column and the introducing the cells by hand but it gives me an error, what am I doing wrong?
Thank you in advance!
Regards
Rodrigo
Hi Rodrigo,
what does the error-message say?
Hello,
Thank you very much for this function. It’s really helpful.
Is there a way I can import several sheets from the same workbook, each one with a different range, all at the same time?
Thank you in advance
Hi Teresa,
that should be possible: Just create a table with one column for each function parameter and a row each sheet that you want to import.
Then create a custom column where you invoke this function. That will return the content of the sheets in every row.
/Imke
“An error occurred in the ‘’ query. Expression.Error: There weren’t enough elements in the enumeration to complete the operation.
Details:
[Table]”
Parameters:
– File path: C:\hai\Operations.xlsx
– Sheet: test
– StartCell: A1
– EndCell: A2
Any ideas? Thanks
This error message could mean that the file or the sheet wasn’t found, so please check spelling.
And be aware the M is case sensitive.
thanks for your efforts to make our Excel life easier, lot easier!
Hi,
I need your help in achieving below.
– A folder contains many excel file say around 10
– Each excel file has many sheets
– Each sheet is typical.
– We have to export or get data from range of cells say B3 to J10 from all sheets.
Please help me by giving the steps to do.
Thanks,
Pavithra
Seems to not work on *.xls as oposed to *.xlsx
Hi Jaap,
sorry to hear that you’re experiencing problems with it.
I just tested it again on a xlsx to check if anything has changed in the file format since I posted this, but everything worked out fine.
Did you check the limitations that I mentioned in the blogpost?
What does the error-message say?
/Imke
Hi Team,
Just wanted to know if the Data souce changes for Example: Onedrive or sharepoint.files, than how will this work ..
If there is a parameter or a loop to check if the link : start with sharepoint or http: is it possible.
Thanks
Hi! Thanks for this useful function!
I would like to select a specific range of cells but for all the excels workbooks into a folder, then combine them like we can do usually. Does someone have such a function that permits to do so? Thanks a lot
how to call file from share point using this function ?