
This article describes the use of Expression.Evaluate as a very helpful “swiss-army-knife”-method for your Power BI toolbox as it has many more use cases than the one described below. It lets you perform repeating tasks without using functions and can even replace recursive operations in some cases – but that’s a topic for a later blogpost. Today we start with a simple task:
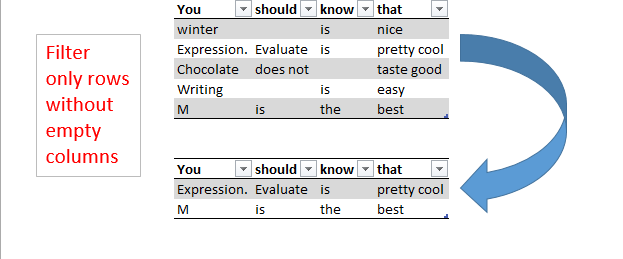
If you want to filter rows only where none of the fields/columns are empty, you’d either pass not-null filters into every single column (which is tedious and not dynamic), transpose or add an index column, unpivot and filter from there (both might drag performance down on large tables).
Using Expression.Evaluate will create a dynamic approach that doesn’t force you to transform your source table nor to directly specify your column names: It will take in a text string and execute it as if you’ve been written it manually into the formula. If you manage to let this textstring be created dynamically according to the different tables you’re going to pass in – Expression.Evaluate will make sure that these individual statements will be executed accordingly.
So for a table containing Column “A” and Column “B” the filter statement would look like this:
FilteredTable = Table.SelectRows(Source, each [A] <> null and [B] <> null)
And for a table with columns “You”, “should”, “know”, “that” like this:
FilteredTable = Table.SelectRows(Source, each [You] <> null and [should] <> null and [know] <> null and [that] <> null)
So what stays the same is the blue one and what needs to be dynamically created is the red/green one.
You’d call it like this:
FilteredTable = Table.SelectRows(Source, each Expression.Evaluate(Expression))
So how to automatically create the Expression.Evaluate-textstring then?
If we’d have a list of all the red items, we could simply combine them using “and ” as the combiner: Text.Combine(List, “and “)
As a starting point for the list we can take the table header (Table.ColumnNames) and transfer it to a table:

Then add a column that adds the other text-parts:
Table.AddColumn(Custom1, “Text”, each “[“&[Column1]&”] <> null”)
This will create a new column that contains the text parts for our string:

So the expression will then be created like this:

So far for the fun part. If you’re now executing it, you will be greeted with the following error-message:

This error-message is due to the missing definition of the environment as described in Chris Webb’s article linked to above . In this case, it’s pretty simple: [ _ = _ ]. Resulting in:
Table.SelectRows(Source, each Expression.Evaluate(Expression, [ _=_ ]))
As you can read in Chris’ latest blogpost this underscore creates a kind of row-context by passing on all values of the current row. Although it can be omitted in many cases, here we need it.
I was made aware of the tremendous power of Expression.Evaluate by Ivan Bond’s blogpost. But already recognized some potential downsides: You might stop looking for more elegant solutions that some unrecognized M-functions could provide because you can just Express…-code it. …Treasures have their price 🙂
FilterNonEmptyColumns.xlsx
Enjoy & stay queryious 🙂
Hi Imke. Glad to see more people using Expression.Evaluate. One thing to note is that we recommend using the accompanying methods Expression.Constant and Expression.Identifier when creating expressions that will be handed to Expression.Evaluate. This provides a more robust solution (for things like column names that might need to be escaped), and also helps protect against injection attacks.
Thanks a lot Ehren, that’s news to me. Very good to know!
One more thing: this particular scenario is probably better accomplished without the use of Expression.Evaluate. The following is a simpler solution.
= Table.SelectRows(Source, each List.AllTrue(List.Transform(Record.FieldValues(_), (fieldVal) => fieldVal <> null)))
It comes with a price – didn’t I say so?
Thanks again Ehren 🙂
Hi Imke 🙂
I know what you mean about Expression.Evaluate but i this particular case the job is simple :-))
let
Source = Excel.CurrentWorkbook(){[Name=”Tabelle1″]}[Content],
Filter = Table.SelectRows(Source, (x) => not List.Contains(Record.ToList(x), null))
in
Filter
That is all.
sq :-))
Hi Bill,
thanks a lot for this line of beauty! (Prefer that to flowers :-))
sq 🙂
Sorry to necropost but with this one it is also very easy to spot the files that do have nulls. Very useful for exception reporting!
Thanks!
No worries, you’re welcome 🙂
/Imke
Here is another way – now where as elegant as the above solutions – but works
let
Source = Excel.CurrentWorkbook(){[Name=”Tabelle1″]}[Content],
mColNms = Table.ColumnNames(Source),
mReplaceNull = Table.ReplaceValue(Source,null,”|”,Replacer.ReplaceValue,mColNms),
mInsMergedCol = Table.AddColumn(mReplaceNull, “Merged”, each Text.Combine(Record.FieldValues(Record.SelectFields(_,mColNms))), type text),
mFilterRows = Table.SelectRows(mInsMergedCol, each not Text.Contains([Merged], “|”)),
mRemCols = Table.RemoveColumns(mFilterRows,{“Merged”})
in
mRemCols
Of course assumes that the original text does not have the pipe symbol anywhere
Pingback: NULL-Werte in Tabellen mit variablen Spalten finden | THE SELF-SERVICE-BI BLOG
Pingback: The Environment concept in M for Power Query and Power BI Desktop, Part 3 | THE SELF-SERVICE-BI BLOG
Just an FYI – this will fail if the column names have special characters in them. I was getting this error and it was driving me nuts until I did the manual filter to figure out why:
Expression Error [1,127-1,130] Invalid Identifier
Details:
[List]
Super helpful error. :-/
Anyway, the fix is to not reference columns like [Column1] but as [#”Column1″] which ensures any special characters in the column name are handled. So the adjustment to your formula for the Expression is:
each “[#” & Character.FromNumber(34) & [Column1] & Character.FromNumber(34) & “] <> null”
Just one more way to make bulletproof M code!
Oh yes, that’s can bite in many ways.
Thanks for the heads up, Ed!
Ed, instead of concatenating the pound and quotes, you should instead use Expression.Identifier. This will handle additional cases (such as an identifier that itself contains quotes). It also only does the pound-quote escaping when necessary.
Beautiful Ehren! That makes Imke’s Text step =
each “[” & Expression.Identifier([Column1]) & “] <> null”
Much easier!
Best post and Best comments.
I love all of yoooooouuuuuu.
Thanks, you’re welcome 🙂